Web scraping: Difference between revisions
VKranendonk (talk | contribs) |
VKranendonk (talk | contribs) No edit summary |
||
| Line 6: | Line 6: | ||
{{Column}}[[File:Alice Wonderland Scraped.png]]{{ColumnEnd}} | {{Column}}[[File:Alice Wonderland Scraped.png]]{{ColumnEnd}} | ||
{{ColumnsEnd}} | {{ColumnsEnd}} | ||
== Video == | |||
You can follow the video or read the steps below the video. | |||
{{#evt: | |||
service=vimeo | |||
|id=https://vimeo.com/manage/videos/745732932 | |||
}} | |||
== Installing == | == Installing == | ||
Revision as of 10:56, 2 September 2022
Web scraping is used to scrape data such as text and images from websites. In this example we will scrape data from the Gutenberg website.
The purpose of web scraping is to transform web content into usable data for other programs or analysis. In this case we transform the following website into CSV data which can be opened in Microsoft Excel or Numbers.


Video
You can follow the video or read the steps below the video.
{{#evt: service=vimeo |id=https://vimeo.com/manage/videos/745732932 }}
Installing
Step 1:
We will use a browser extension called WebScraper.io. You can install the extension for Firefox or for for Chrome.
To learn about all of the functionality in the WebScraper.io extension you can watch the intro video.
Step 2:
Navigate to Alice’s Adventures in Wonderland on the Gutenberg website.
Step 3:
Right click anywhere on the screen and click "inspect". This will open the inspector, a tool commonly used for debugging websites.

Step 4:
You should now have an extra tab called "Web Scraper Dev". Open this tab.

Creating a selector
Step 5
Create a new sitemap. Call it for example "alice". The start url is the page you are currently on: https://www.gutenberg.org/files/11/11-h/11-h.htm


Step 6
Our goal will be to scrape each title and paragraph.
- Click on "Add new selector".
- Add an "Id" which makes sense, for example "content".
- Set "Type" from "Text" to "HTML". We do this because each paragraph can still have HTML inside it.
- Click "Select". You can now start selecting which elements you would like to scrape. Start with the title and then the paragraphs while holding "shift".
-
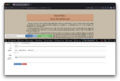 Selecting the first element
Selecting the first element -
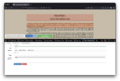 Selecting the second element - while holding shift
Selecting the second element - while holding shift -
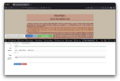 Selecting the next element - while holding shift
Selecting the next element - while holding shift -
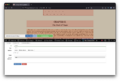 Selecting elements in second chapter - while holding shift
Selecting elements in second chapter - while holding shift




- Click on "Done selecting"
- Check the checkbox for "multiple". Otherwise only the first element will be scraped.
- Click on "Save selector"

Scrape and export data
Step 7
Click on "Sitemap alice" and then on "scrape". Press "Start scraping" to... you guessed it, start scraping 😃.
This will open a new window in which a robot will "scrape" all the content you selected in the previous steps.
When the scraping is done, press the "refresh" button. If all went okay, you should now see some data.
-
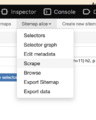 Open the scrape window
Open the scrape window -
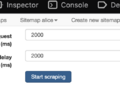 Start scraping
Start scraping -
 Press the refresh button after scraping
Press the refresh button after scraping -
 Tadaah! 🥳 Scraped data.
Tadaah! 🥳 Scraped data.




Step 8
We can now export and download the data.
Press "Sitemap alice" and then "Export data". Click the big blue button ".CSV" to download a CSV file. This file can be opened in Microsoft Excel or Numbers.
-
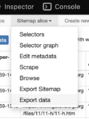 Open the export data window
Open the export data window -
 Download the .csv file
Download the .csv file


Conclusion
Scraping allows us to gather data from the web, which can then be used in another way, for example in an art installation or to build an unique way of browsing the same content.
Scraping can also be automated to run at intervals, for example each week. You could for example scrape music events from different websites and gather those events on your personal agenda page.
What's next. Try scraping other websites and creating multiple selectors. The WebScaper.io intro video is a good place to learn more about selectors.

